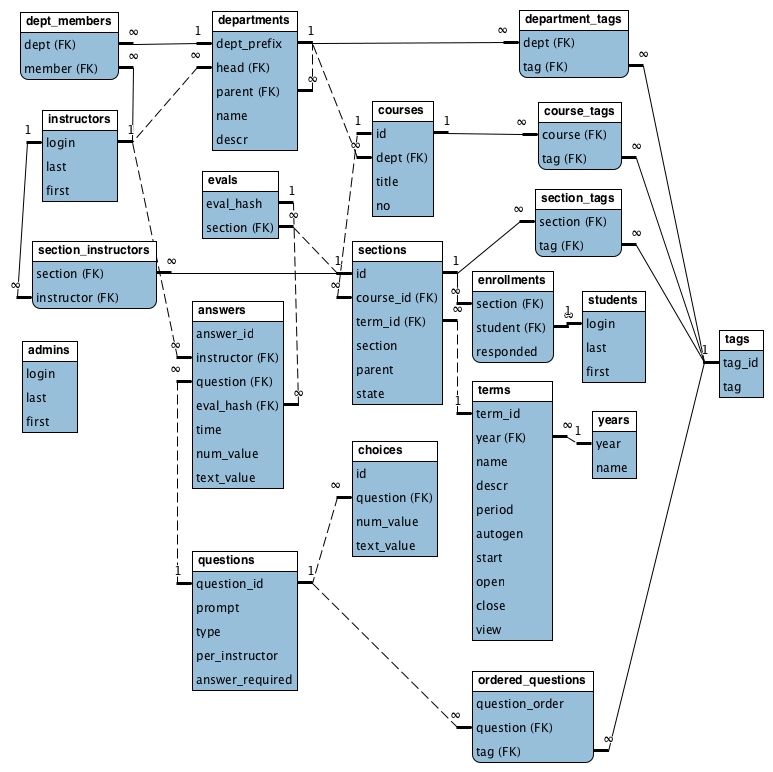
Evaluations Database Relationships
An aggregate is a collection of related objects that we treat as a unit. These aggregates tend to transcend the normalized breakdown that relational databases promote. For example, recall our basic evaluations database structure:
Evaluations Database Relationships
There are many different "aggregates" we could consider. Ultimately what determines an aggregate has to do with the kinds of queries one might want to perform.
We could consider an "evaluation", which would contain in it the various questions and answers pertinent to that evaluation. In JSON terms, it may look something like this:
{
"evalHash": ".....",
"sectionId": ".....",
"answers": [
{
"questionId": ".....",
"questionPrompt": ".....",
"questionType": ".....",
"instructor": ".....",
"answerNum": ".....",
"answerText": "....."
},
.....
]
}We could consider a "section" object, which would contain more details about the course and instructors, rather than simply linking to those tables. And it may further contain the various student enrollment lists and evaluation lists. So it may look something like this:
{
"sectionId": ".....",
"courseId": ".....",
"fullName": ".....",
"term": {
"year": ".....",
"period": "....."
},
"status": ".....",
"instructors": [
{
"name": ".....",
"id": "....."
},
.....
],
"enrolled": [
{
"studentId": ".....",
"studentName": ".....",
"completed": "....."
},
.....
],
"evaluations": [
{
"evalHash": "...",
},
{
"evalHash": "...",
},
.....
]
}The idea is that aggregates tend to put together all the information that will tend to be processed together. This simplifies and speeds up those queries that respect this unit of interaction.
On the other hand, it also makes other queries more complicated. Suppose for example that we wanted to get summary information about all student answers to a particular question. With our aggregate example above, we have essentially two approaches:
So bottom line: In aggregate data models, some queries that respect the aggregate structure are fast, while other queries that transcend the structure become harder to perform.
Both key-value stores and document databases emphasize an aggregate-oriented design: Each aggregate is identified by its id/key and treated as a unit.
The difference between the two is on how the contents of the aggregate are treated: